Personal Finance - Tracking your monies
(Again, this is a work in progress... Why do I keep publishing things before they're done????)
I want to get better at tracking wealth. I have a spreadsheet that I update once a quarter that tracks what I own, owe, and (doh! I can't think of a clever o-word to use here.) I would like to build something that monitors those things in almost real time (daily updates at least) and goes a little deeper than cash value. That is, for each asset, I would like to know:
- the resource's allocation
- stock
- large cap
- mid cap
- small cap
- foreign
- bond
- cash (USD)
- foreign equity
- real estate
- insurance
- private equity
- personal asset
- liability
- mortgage
- some other loans?
- stock
- where it sits
- IRA
- ROTH
- health spending
- investment account
- bank
- when it was purchased and when it will end
- basis (this gets complicated when you, for example, purchase more shares of the same stock. I guess just treat it like a brand new stock at that point. What about splits?
- the ending date for things like a CD
- what kind of returns for known accounts
- bank rates
So, yeah, this gets complicated if you let it. I'm not sure if I should continue down the path of a spreadsheet or throw together a project. Getting daily updates for stocks and funds makes me thing an app is the route I need to take.
Until then!
Using the Kelly Criterion to Manage a Bankroll in Stock Markets
why the hell not
I stumbled upon an interesting sentence while working my way through "An Introduction to Statistical Learning with Applications in R." By the way, the book is available for free here. You should check it out! I don't have any strong opinions on how useful it is, yet, for I only just started reading. But, so far so good.
About that sentence. It says:
Nevertheless, in Chapter 4, we explore these data using several different statistical learning methods. Interestingly, there are hints of some weak trends in the data that suggest that, at least for this 5-year period, it is possible to correctly predict the direction of movement in the market approximately 60% of the time
I immediately thought that this might be an excellent exercise to learn how the Kelly Criterion could be used to optimize returns. The Kelly Criterion is a method to determine the optimal size of a series of bets each of which is given by (directly from wikipedia )
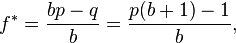
where:
- f* is the fraction of the current bankroll to wager, i.e. how much to bet;
- b is the net odds received on the wager ("b to 1"); that is, you could win $b (on top of getting back your $1 wagered) for a $1 bet
- p is the probability of winning;
- q is the probability of losing, which is 1 − p.
The idea is if you invest (bet) according to the formula, you will do better in the long run than had you used any different betting strategy. When I read the sentence about being able to reliably predict the market's direction I thought it might be fun to apply the Kelly Criterion to see what kind of returns you could get.
If you're paying attention, you might have noticed the formula that requires you to know the net odds received on the bet. That is, you not only have to know the direction, but also the magnitude. Doh! Let's not let that stop us from seeing if we can get some results.
The book uses Quadratic Discriminant Analysis (QDA) to fit an QDA model to stock market data to predict the direction of market movement over a period of time. The dataset consists of percentage returns for the S&P 500 over 1, 250 days from 2001 to the end of 2005. The idea is to use the percent return for each of the previous five days and the volume traded on teh previous day to predict direction. Once the model is trained, you can run the predict() function to get the probability of the market direction given five days of previous percent changes and the previous day's volume. In other words, feed the predict function the right data and make a trade based on what the function says to do. You have a 60% chance of being correct.
Wasn't I talking about the Kelly Criterion a minute ago? Yes! I was. If you have an edge (that is, a greater than 50% chance of winning) there is an optimal betting strategy that will maximize your returns while guaranteeing your bank roll won't go to zero.
Let's pretend we are investing in an S&P 500 ETF. Ignoring taxes and transaction costs (of course) your strategy is to buy at market open and sell at market close. If the market is predicted to go up, buy long. If the market is predicted to go down, short the ETF. How much you buy is defined by the Kelly Criterion function defined above. p = 60% but what is the net odds? Let's be naive and compute it as the volatility for the previous five days.
install.packages("ISLR")
library(ISLR)
library(MASS)
summary(Smarket)
attach(Smarket)
plot(Volume)
train=(Year <2005)
Smarket.2005= Smarket [! train ,]
dim(Smarket.2005)
Direction.2005=Direction[!train]
qda.fit=qda(Direction~Lag1+Lag2,data=Smarket ,subset=train)
qda.fit
Call:
qda(Direction ~ Lag1 + Lag2, data = Smarket, subset = train)
Prior probabilities of groups:
Down Up
0.491984 0.508016
Group means:
Lag1 Lag2
Down 0.04279022 0.03389409
Up -0.03954635 -0.03132544
qda.class=predict(qda.fit,Smarket.2005)$class
table(qda.class ,Direction.2005)
mean(qda.class==Direction.2005)
export it to csv
write.csv(Smarket.2005, file="/tmp/Smarket.2005.csv")
write.csv(qda.class, file="/tmp/qda.class.csv")
I exported it to csv so I could work with it in python and pandas because I'm more comfortable in that environment
and I'm not sure there are any examples using pandas on this site, yet. I use it way more than I use r,
believe it or not.
Ok, so,
Smarket.2005.csv has rows numbered 999-1250 and qda.class.csv has rows numbered 1-252 which means the rows will line
up. Let's pull them into ipython notebook.
Aaaand, it is bed time. BUT, there isn't much more to do other than show gain/loss for each day using the Kelly Criterion starting with a $10,000 bank roll.
Tech Unicorns
This is not a complete entry
There has been a lot of talk about unicorns lately, or, at least, I'm getting a nice Baader-Meinhof phenomenon for unicorns. At any rate, I think Aswath nicely illustrates some fuckery that can be done in valuation during an up round. It is nicely explained here:
http://aswathdamodaran.blogspot.com/2015/06/billion-dollar-tech-babies-blessing-of.html
And then there is this analysis of biotech unicorns and the idea that maybe it is better to invest in a basket rather than one:
http://mebfaber.com/2015/06/17/would-you-rather-own-the-unicorns-or-facebook/
In that article there is a link to a slideshare that, in fact comes from a bennedict evans post. You might as well check that out, too:
http://ben-evans.com/benedictevans/2015/6/15/us-tech-funding
fascinating stuff.
Real Analysis and Measure Theory
Not as scary as you might think
Do you know anything about real analysis and measure theory? I was thinking about a gambling problem I couldn't figure out and dug in to find out why. I still don't have an answer, but I learned that measure theory isn't as scary as I thought. If you don't know anything about it, these are two, very accessible introductions:
why use measure theory for probability part 1 - https://www.youtube.com/watch?v=RjPXfUT7Odo&feature=player_embedded
intro to brownian motion and the ito integral part 1 - https://www.youtube.com/watch?v=fEsnMyi5-8k&list=PLC7A868A384F6EFF0
here is the guy from the first video http://www.math.missouri.edu/~evanslc/
Terrance Tao's boodk http://terrytao.files.wordpress.com/2012/12/gsm-126-tao5-measure-book.pdf
A really simple intro to financial math from a cs teacher https://www.youtube.com/playlist?list=PL1BaGV1cIH4UXkZgrX2TtXhvUQW6_4hZF
he also has a site for these videos, might want to check out the probablility refreshers for FE's: http://byrnetube.com/mathematicalFinance.php
this all started from some guy's comments about measure theory on this "how to quant" HN post https://news.ycombinator.com/item?id=8698986
I want to do a calc refresher. Here are some resources for doing that:
calc refresher (See notes) https://news.ycombinator.com/item?id=2258794 http://ocw.mit.edu/resources/res-18-006-calculus-revisited-single-variable-calculus-fall-2010/ http://ocw.mit.edu/resources/res-18-005-highlights-of-calculus-spring-2010/ http://ocw.mit.edu/ans7870/resources/Strang/Edited/Calculus/Calculus.pdf
Mathematics: Its Content, Methods and Meaning - preview on books.google.com available at Olin Level B Stacks QA36 A453 in all three parts. And it is only $25 on amazon http://www.amazon.com/Mathematics-Content-Methods-Meaning-Dover/dp/0486409163/
And also i should read Sheldon Axler's "Linear Algebra Done Right"
Damodaran and Trunk Recording
ramblings of the day
Per the damodaran finance class i'm listening to, the risk free rate basically boils down to the expected rate of inflation in the currency in which you are working. (This is the sound of lightbulbs going off in my head.) Rule of thumb - Use the 10 year zero coupon rate for the risk free rate if the bond is rated AAA. If it is not rated AAA, then take the published rate and subtract off any default risk. You do this because often you will add in default risk at a different point in your analysis. You do not want to double count.
For me, this is kind of huge. I always thought of the risk free rate as the minimum return you could possibly expect with zero risk of default. Which, sure, that's true, but understanding that the market essentially drives that number to track expected inflation of the currency in which you are investing helps me to better understand the fact that different countries have wildly different risk free rates. I never knew why you wouldn't just shift currencies around to get the best deal.. well, i forgot to think about inflation.
update 20120519 - Heh, in lecture 6 he said that the risk free rate is really inflation + macro market growth. I guess that makes sense, too. Still learning
The difference between html's bold and strong tags and italic and emphasis tags eludes me.
Let's talk about hidden markov models. No, really, someone teach me because I ran out of copy paper this week and wound up using all the papers I printed out that I hoped would help me understand them as printer paper. Dammit.
I love John Steinbeck's letter that is on letters of note today:
"If there is a magic in story writing, and I am convinced that there is, no one has ever been able to reduce it to a recipe that can be passed from one person to another. The formula seems to lie solely in the aching urge of the writer to convey something he feels important to the reader. If the writer has that urge, he may sometimes but by no means always find the way to do it."
I know I'm no writer, but everything on this site and armp.it is from me getting this compulsive need (out of nowhere, typically) to put a certain feeling into words and most of the time it doesn't work. Or, rather, I Get It.
I'm putting together a comment service for the app i'm building. I think my implementation is interesting. Here's how i'm doing it. Everything in my system uses a UUID as its ID or primary key. Everything, including each comment. Each comment stores the UUID of the item to which it is attached, the comment text, timestamp, etc. All comments are shoved into this service so that when something says, "I want to display any comments associated with me." All it has to do is pass its UUID to the service which returns a (JSON) list of comments.
Easy peeeezy
The challenge here is how do you go from Comment to the Item. Well, since I don't store the Item's location we fall back to a searching pattern. Every item is indexed anyway, so we just hit the search service with the UUID and get the item back.
This is completely decoupled. It fails if you delete an Item (which, of course, you NEVER delete anything. So, that's not a problem.) Or, if you need to move the comments. Not sure why you would do that, though.
Finally, you can comment on comments. So, your comments can have comments that comment about the comments.

I'm recording guitar parts in my car again while I wait for band practice to start. YOU CAN RECORD DECENT SOUNDING ALBUMS WHILE SITTING IN YOUR CAR. I love the present.